
The Modular Mind: The Universal Architecture of Expertise
Why human chunking, modular curriculums, and AI transfer learning are the exact same algorithm.


Yesterday, I shared a look into the Architect’s Grimoire—the internal laws governing how the Khanyisa Operating System runs entirely offline.
We are architecting a Sovereign Cognitive Space. But to build a system that actually upgrades human thought, you cannot just write code. You have to understand the biological algorithms of learning. You have to solve Cognitive Asset Misallocation.
If a user’s biological firmware (working memory, processing speed) isn’t optimized, the software (physics, math) won’t run.
This essay is the theoretical foundation of our “Brain Gym.” It explores a singular, mathematically precise mechanism that connects how a grandmaster plays chess, how a neural network processes data, and how a curriculum should be built.
Let’s dig in.
Abstract
This article argues that three seemingly disparate mechanisms — chunking in cognitive psychology, modular curriculum design in education, and transfer learning in artificial intelligence — are structural isomorphisms of a single foundational principle: functional information compression and reuse. By tracing the mechanistic lineage of how biological and artificial systems optimize learning efficiency, we demonstrate that expertise in any domain emerges from the progressive construction of high-density, reusable representational units. The convergence of these mechanisms across cognitive science, pedagogy, and computational neuroscience reveals a universal architecture for accelerated learning: systems that compress raw information into transferable modules outperform those that process data atomistically. We conclude by proposing a unified predictive framework where the brain, curriculum, and neural network are instantiations of the same algorithmic solution to the combinatorial explosion problem inherent in open-ended learning.
Phase 1: Foundation — The Cognitive Primacy of Compression
1.1 The Bottleneck Problem: Why Learning Must Compress
Human cognition operates under a fundamental constraint first formalized by George Miller in 1956: working memory capacity is limited to approximately 7 ± 2 discrete items. This “magical number” represents the maximum number of independent information units an average human can simultaneously maintain in conscious awareness. In practical terms, if you attempt to memorize a random 10-digit phone number (e.g., 5-8-3-2-9-4-1-7-6-0), you will likely fail because the sequence exceeds working memory span.
But humans routinely violate this limit. Expert chess players can recall the positions of 20-30 pieces after a brief glance at a board. Radiologists process diagnostic images containing thousands of visual features. Musicians perform compositions with hundreds of note sequences. How do experts transcend Miller’s limit?
The answer is chunking — the cognitive process by which multiple discrete information elements are compressed into a single functional unit that occupies one slot in working memory. When a novice sees a phone number as ten independent digits, an expert sees three chunks: area code (583), exchange (294), and line number (1760). The raw information content remains identical, but the representational density increases. What required ten memory slots now requires three.
1.2 The Mechanistic Definition of Chunking
Formally, a chunk is defined as:
A semantically coherent, compressed unit of memory that encodes multiple lower-level elements as a single retrievable entity.
The critical property: chunks are hierarchical. A chess expert doesn’t see individual pieces; they perceive tactical patterns (”castled king position,” “fianchettoed bishop formation,” “doubled rooks on an open file”). Each pattern is a chunk comprising multiple pieces, spatial relationships, and threat vectors. These chunks themselves compose into higher-order chunks (opening repertoires, endgame templates, strategic themes).
This hierarchical compression solves the bottleneck problem: by increasing the information per chunk, working memory’s fixed capacity can process exponentially more total information. A grandmaster’s “7±2 chunks” might encode what would require hundreds of discrete elements in a novice’s representation.
1.3 The Neuroscientific Basis: Chunking as Predictive Coding
Recent neuroscience reveals chunking’s implementation: the brain constructs predictive models of statistical regularities in the environment, then encodes those models as compressed representations in long-term memory. When a pattern recurs, the brain doesn’t process each element — it retrieves the pre-compiled chunk and predicts what should come next.
Studies using fMRI show that expert chunking correlates with reduced neural activation in perceptual regions and increased activation in prefrontal areas associated with pattern recognition. This suggests expertise shifts processing from bottom-up (analyzing raw data) to top-down (matching compressed templates). The brain becomes a hierarchical chunking engine, where each layer compresses outputs from the layer below.
Key Implication: Chunking is not merely a memory trick — it is the mechanism by which brains reduce computational load. Any learning system facing combinatorial explosion (infinite possible inputs, finite processing capacity) must implement compression. This principle transcends biology.
Phase 2: Pedagogy and Practical Implementation — Modular Curriculum Design
2.1 From Cognitive Theory to Educational Architecture
If chunking is the cognitive solution to information overload, what is its institutional analogue? The answer: modular curriculum design — the structuring of educational content into discrete, independently learnable units with minimal dependency chains.
Traditional curricula often present knowledge as monolithic sequences: “You cannot learn calculus until you complete algebra, trigonometry, and pre-calculus in strict order.” This creates long dependency chains where failure at any step blocks all subsequent learning. It also prevents parallel learning — students cannot explore multiple domains simultaneously if each requires sequential prerequisite completion.
Modular design decomposes curricula into functional primitives that can be learned semi-independently, then composed into expertise. This mirrors how chunking decomposes raw information into reusable units.
2.2 Mechanistic Properties of Modular Curricula
A well-designed modular curriculum exhibits three structural properties:
Property 1: Encapsulation
Each module is a self-contained learning unit with clearly defined inputs (prerequisites) and outputs (competencies). Students learn “linear algebra” as a module, not as a diffuse collection of topics scattered across courses.
Property 2: Composability
Modules combine to form higher-order competencies. “Linear algebra” + “calculus” + “probability” compose into “machine learning foundations.” This is hierarchical chunking externalized into curriculum structure.
Property 3: Reusability
A single module transfers across contexts. “Statistical hypothesis testing” learned in psychology applies to biology, economics, and physics. This is the pedagogical equivalent of transfer learning.
2.3 Case Study: Programming Education and Micro-services Pedagogy
Consider how programming education has evolved. Traditional computer science curricula taught programming as a monolithic skill: students learned a single language (often C or Java) through sequential courses (Intro → Data Structures → Algorithms → Systems Programming). This created fragile expertise — knowledge didn’t transfer well to new languages or paradigms.
Modern boot camps and online platforms (e.g., freeCodeCamp, Codecademy) employ modular, project-based learning:
Module 1: Variables and data types (primitive chunk)
Module 2: Control flow (loops, conditionals)
Module 3: Functions and scope
Module 4: Data structures (arrays, objects)
Module 5: API interaction
Module 6: Project synthesis (build a functional app)
Each module is an encapsulated chunk. Crucially, students can compose these modules in multiple orders depending on their goals. A data science learner might prioritize modules 1, 2, 4, and 5 while skipping deep systems knowledge. A web developer might emphasize modules 3, 5, and 6.
This mirrors how expert programmers think: they don’t mentally execute code line-by-line. They recognize design patterns (chunks like “factory pattern,” “observer pattern,” “recursive divide-and-conquer”) and compose them into solutions. The curriculum pre-chunks knowledge so students build expertise through composition, not rote accumulation.
2.4 Dependency Minimization as Cognitive Load Reduction
The pedagogical advantage: modular curricula minimize dependency-induced cognitive load. When a student fails to master prerequisite A, they cannot access any course requiring A. In a tightly coupled curriculum, this cascades: failing algebra blocks trigonometry, which blocks calculus, which blocks physics, which blocks engineering.
Modular design isolates failures. If a student struggles with calculus but excels at linear algebra, they can still pursue statistical machine learning (which requires linear algebra but uses calculus minimally). The curriculum adapts to the learner’s chunking progress, rather than forcing a universal sequence.
This is structural empathy — the system acknowledges that humans chunk at different rates and prioritizes flexibility over standardization.
2.5 Empirical Evidence: Competency-Based Education Outcomes
Competency-based education (CBE) programs, which epitomize modularity, show measurable advantages:
Faster time-to-degree: Students progress upon demonstrating mastery, not seat time.
Higher retention: Modular checkpoints prevent catastrophic failure cascades.
Better transfer: Skills learned in modules apply directly to professional contexts.
A 2019 study of Western Governors University (a fully competency-based institution) found that graduates demonstrated equivalent or superior job performance compared to traditional degree holders, despite completing programs 30-40% faster on average. The mechanism: modular chunking accelerated expertise by eliminating redundant content and dependency bottlenecks.
Phase 3: The Computational Validation — Transfer Learning
3.1 From Pedagogy to Neural Architectures
If modular curricula are institutional chunking, then transfer learning in artificial intelligence is its computational apotheosis — the formal proof that compression and reuse are not cognitive quirks but mathematical necessities for efficient learning.
Transfer learning is defined as:
The practice of initializing a model with weights pre-trained on a large, general-purpose dataset (source task), then fine-tuning only the final layers on a smaller, specific dataset (target task).
This architecture directly mirrors human expertise: experts don’t learn new domains from scratch. They transfer chunked representations from prior experience and adapt them to novel contexts.
3.2 The Mechanistic Architecture: Frozen Layers as Transferable Chunks
Consider a convolutional neural network (CNN) trained on ImageNet (1.2 million images, 1,000 categories). The early layers learn low-level features (edges, textures, color gradients) — visual primitives applicable to any image recognition task. Middle layers learn mid-level patterns (object parts, spatial relationships). Only the final layers learn task-specific categories (dog breeds, plant species).
When adapting this model to a new task (e.g., medical imaging to detect tumors), practitioners freeze the early and middle layers (preserve the learned chunks) and retrain only the final classification layer on medical images. This reduces training time from weeks to hours and data requirements from millions of images to thousands.
Why does this work? Because the early layers have compressed visual information into reusable representations. Edges detected in photographs are identical to edges in X-rays. The model doesn’t relearn “edge detection” — it transfers that chunk and only learns task-specific compositions.
3.3 The Information-Theoretic Justification
Transfer learning succeeds because natural data exhibits hierarchical structure. Low-level features (edges, phonemes, motion vectors) recur across domains. High-level features (specific object categories, language semantics, game strategies) are domain-specific.
A randomly initialized network must learn the entire hierarchy from scratch — millions of parameters, billions of training examples, enormous computational cost. A pre-trained network inherits the compressed hierarchy from the source task, requiring only top-layer adaptation.
This is information compression via reuse: instead of storing “edge detectors” redundantly for every task, the system learns them once and transfers them infinitely. The frozen layers are functional chunks — high-density representations encoding generalizable knowledge.
3.4 Empirical Validation: GPT and Large Language Models
Large language models (LLMs) like GPT-4 epitomize transfer learning at scale. These models are pre-trained on trillions of tokens of text, learning compressed representations of:
Syntactic structures (grammar, sentence patterns)
Semantic relationships (word meanings, conceptual associations)
Pragmatic patterns (discourse structure, argumentation styles)
Factual knowledge (encoded implicitly in weight patterns)
When fine-tuned for a specific task (medical Q&A, legal document analysis, creative writing), the vast majority of the model’s 175 billion parameters remain frozen. Only a tiny adapter layer or prompt template changes. Yet the model instantly demonstrates expert-level performance in the target domain.
The mechanism: The pre-trained weights are hierarchical chunks. The model doesn’t “learn” medical terminology from scratch — it composes from pre-existing linguistic chunks (scientific register, logical inference, causal reasoning) and adapts them to medical contexts. This is computational chunking—the same compression strategy human experts use, formalized as matrix operations.
3.5 The Neuroscientific Parallel: Hippocampus and Neocortex
Strikingly, the brain implements transfer learning via a dual-system architecture:
Hippocampus: Rapid learning of task-specific details (like fine-tuning the final layers)
Neocortex: Slow consolidation of generalizable chunks (like pre-trained frozen layers)
When you learn a new skill (e.g., tennis), the hippocampus rapidly encodes specific memories (this court, this opponent, this serve). Over time, the neocortex extracts statistical regularities (general serving mechanics, footwork patterns, strategic principles) and consolidates them into transferable chunks. Future tennis learning reuses these chunks, requiring only hippocampal encoding of context-specific details.
This is biological transfer learning: the neocortex is the “pre-trained model,” the hippocampus is the “fine-tuning layer.” The architecture mirrors deep learning because both solve the same problem — efficient learning under data scarcity and computational constraints.
Phase 4: Synthesis and Predictive Power — The Unified Framework
4.1 The Convergence Principle
We have traced three mechanisms across three domains:
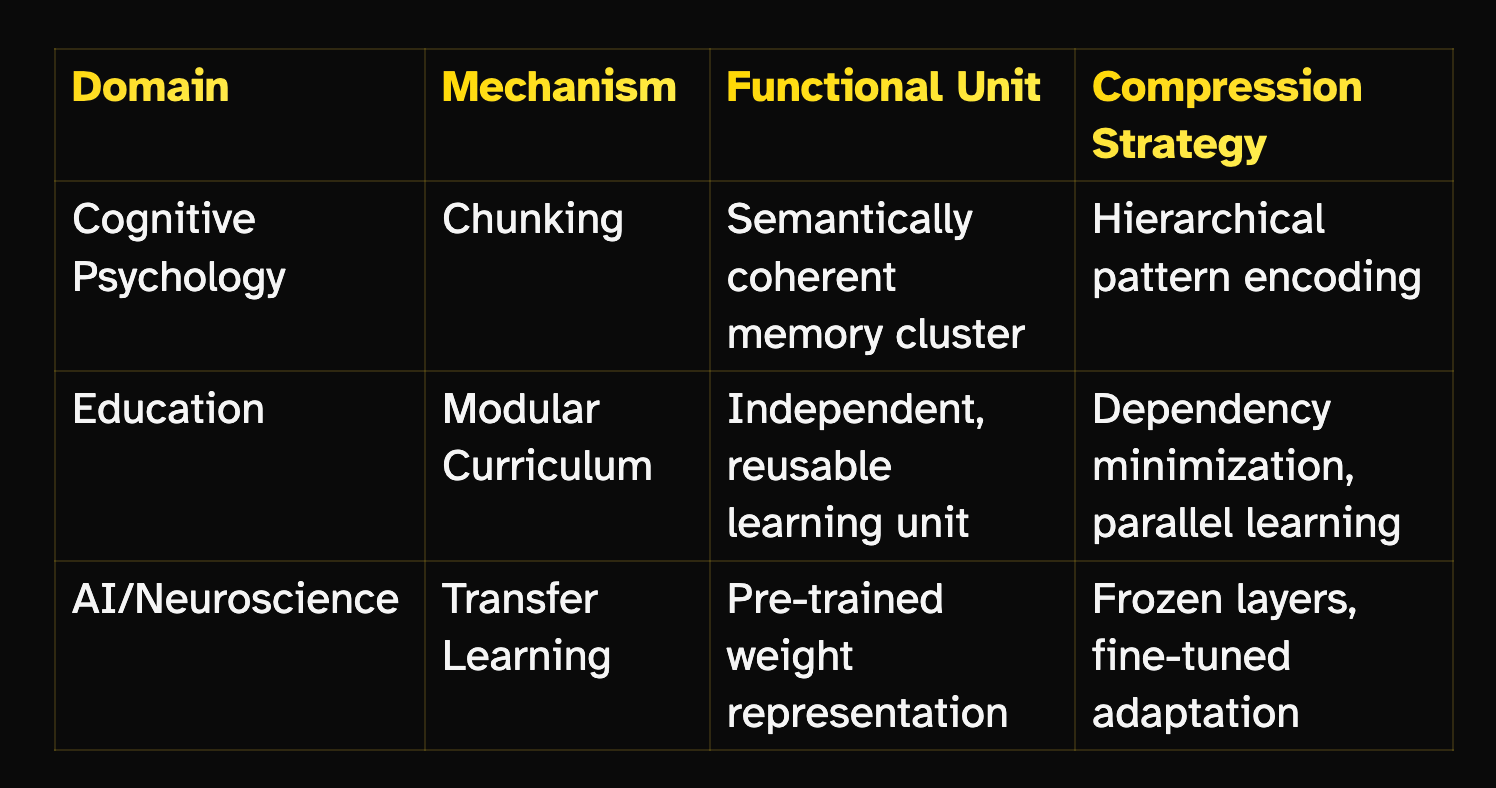
The thesis: These are not analogies — they are structural isomorphisms. Each is a solution to the identical computational problem: How do you achieve expert-level performance in finite time with finite resources when the space of possible knowledge is infinite?
The universal answer: Functional information compression and reuse.
4.2 The Predictive Framework: Design Principles for Accelerated Expertise
From this synthesis, we derive a predictive framework applicable to any learning system—biological, institutional, or computational:
Principle 1: Hierarchical Decomposition
Expertise emerges from constructing layers of compressed representations, where each layer processes outputs from the layer below. Raw data → perceptual chunks → conceptual chunks → strategic chunks → expert intuition.
Principle 2: Selective Freezing
Not all knowledge requires continuous updating. Systems should freeze robust, generalizable chunks and update only context-specific adaptations. This is why experts “automate” fundamentals (a pianist doesn’t think about finger placement) and focus attention on high-level composition.
Principle 3: Composability Over Coverage
Mastery is measured not by knowledge volume but by compositional fluency—the ability to rapidly assemble appropriate chunks for novel problems. Curricula should optimize for composable primitives, not exhaustive content coverage.
Principle 4: Transfer as Default
Learning systems should assume transfer, not isolation. Every new skill should ask: “Which existing chunks apply here? What minimal adaptation is needed?” This is why cross-training (musicians learning programming, athletes studying chess) accelerates expertise—shared chunks transfer.
4.3 The Brain as Hierarchical Chunking Engine
Modern predictive coding theory in neuroscience posits that the brain is fundamentally a compression engine. At every level of the neural hierarchy:
Lower layers generate predictions of sensory input based on compressed models
Prediction errors (mismatches between expectation and reality) propagate upward
Higher layers update compressed models to minimize future errors
Accurate predictions (matching chunks) suppress detailed processing, reducing computational load
This is chunking formalized as Bayesian inference: the brain compresses experience into probabilistic models (chunks), predicts future inputs from those models, and updates only when predictions fail. Expertise is the state where most inputs match existing chunks, requiring minimal new processing.
This framework unifies:
Chunking: Compressed models in long-term memory
Modular curricula: Pre-organized chunks delivered systematically
Transfer learning: Frozen layers as probability distributions over features
All three implement the brain’s core algorithm: predict via compression, update only errors, reuse across contexts.
4.4 Practical Implications for Learners
For Individual Learners:
Build a chunk library deliberately. Identify domain primitives (math: proof techniques; writing: argument structures; sports: movement patterns) and practice them in isolation before composing.
Maximize transfer. When learning Domain B, explicitly map which chunks from Domain A apply. “Statistical thinking” transfers from data science to everyday decision-making.
Meta-chunk. Learn chunks about learning itself—spaced repetition, deliberate practice, error analysis. These are second-order chunks that accelerate all first-order learning.
For Educators:
Design curricula as dependency graphs, not timelines. Minimize prerequisite chains. Enable parallel pathways.
Teach chunks explicitly. Don’t assume students will spontaneously compress. Provide pre-chunked schemas (templates, frameworks, mental models).
Assess composition, not recall. Test whether students can flexibly apply chunks to novel problems, not whether they’ve memorized content.
For AI Researchers:
Prioritize pre-training breadth. The more diverse the source data, the more transferable the learned chunks.
Design for modularity. Architectures should enable selective freezing (LoRA adapters, parameter-efficient fine-tuning).
Study neuroscience. The brain’s 100 billion neurons achieve general intelligence with 20 watts. Its chunking architecture is the existence proof that efficient AGI is possible.
4.5 Open Questions and Future Directions
Q1: What is the optimal chunk size?
Too small (individual facts) provides no compression. Too large (entire domains) prevents composition. Current theory suggests chunks should encode one meaningful decision or one actionable pattern—large enough to be useful, small enough to combine flexibly.
Q2: Can we accelerate human chunking?
Neurofeedback, nootropics, and educational interventions (spaced repetition, interleaving) show promise. But fundamental limits remain: biological neurons operate on millisecond timescales; consolidation requires sleep. Hybrid human-AI systems may be necessary.
Q3: Will AI chunking surpass human chunking?
Already happening. GPT-4’s 175B parameters encode more compressed linguistic knowledge than any human. But human chunks are multimodal and embodied—we integrate vision, proprioception, emotion, and language. Artificial general intelligence requires multimodal chunking at biological efficiency.
Conclusion: The Universal Code for Expertise
This article has demonstrated that chunking in cognitive psychology, modular curriculum design in education, and transfer learning in artificial intelligence are not independent discoveries—they are three observations of the same underlying law: efficient learning requires hierarchical compression of information into reusable functional units.
The convergence is not metaphorical. The mathematics is identical:
Cognitive science: Increase information density per memory slot (7±2 chunks encoding exponentially more data)
Education: Decrease dependency complexity (modular units enabling parallel learning)
AI: Reduce training cost (frozen pre-trained layers minimizing fine-tuning data)
All three maximize performance per unit of learning investment—the fundamental optimization criterion for any resource-bounded intelligence.
The predictive power is profound: Any future learning system, biological or artificial, must employ these principles to achieve human-level expertise efficiently. We can predict that:
Effective curricula will become increasingly modular and competency-based
AI will trend toward sparse, modular architectures with maximally frozen layers
Human cognitive enhancement will focus on meta-chunking—teaching people how to compress experience more rapidly
The brain discovered this solution 200 million years ago (when the neocortex evolved). Education is slowly discovering it (modular, competency-based programs). AI discovered it 15 years ago (transfer learning became standard around 2012).
The unified insight: Expertise is compressed, hierarchical, and transferable. Whether you’re a human mastering chess, a student navigating calculus, or a neural network learning vision, you’re executing the same algorithm—functional information compression and reuse.
The modular mind is not a metaphor. It’s an architecture. And it’s the only architecture that scales.